1. Processor and GPU Microarchitecture
The Rise of General-Purpose GPUs (GPGPUs)
Originally developed specifically to accelerate graphics processing, GPUs are inherently designed to execute a massive volume of independent instructions simultaneously. As multi-core processors became the industry standard, the computing paradigm shifted heavily toward parallel programming to maximize efficiency. Recognizing this architectural advantage, modern GPUs have been extended to support general-purpose computational workloads. By making these massively multi-core processors fully programmable, the era of General-Purpose Computing on Graphics Processing Units (GPGPU) was established.
What We Are Doing
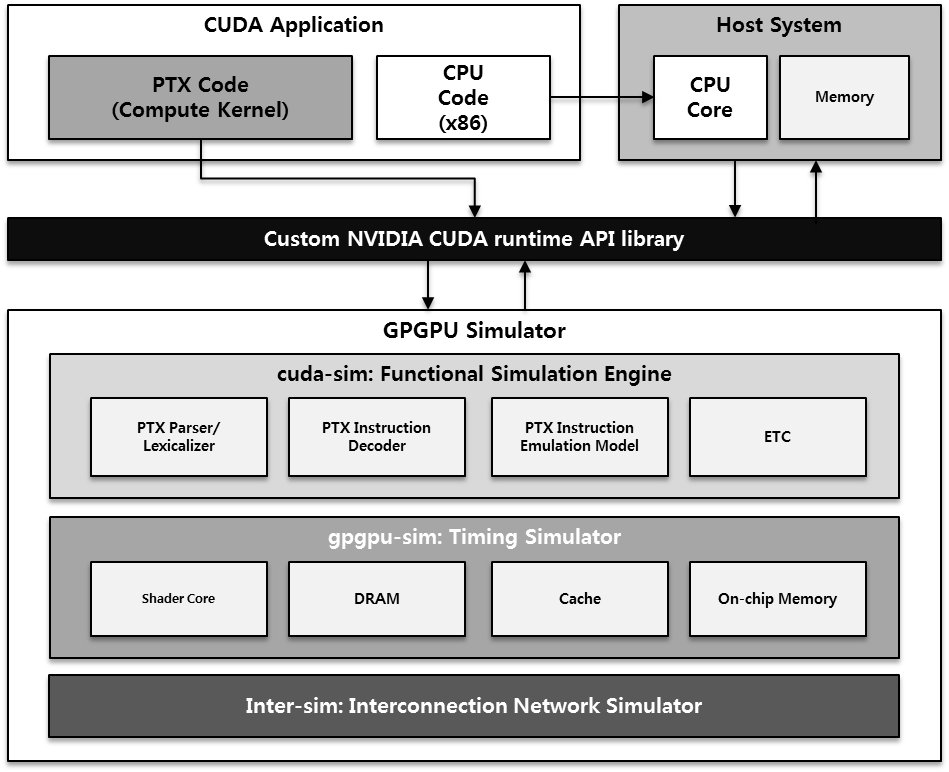
Our lab models and optimizes GPGPU architectures to maximize both performance and energy efficiency. We focus deeply on the underlying hardware pipelines and the complete memory hierarchy—spanning local, global, constant, texture, and shared memory, alongside registers and interconnection buses. To rigorously evaluate our proposed architectural innovations, we utilize detailed C/C++ simulators to virtually execute and analyze complex workloads written in CUDA.
Recent Publications:
- [MICRO'25] "LATPC: Accelerating GPU Address Translation Using Locality-Aware TLB Prefetching and MSHR Compression"
- [ISCA'25] "Heliostat: Harnessing Ray Tracing Accelerators for Page Table Walks"
- [ISCA'25] "Avant-Garde: Empowering GPUs with Scaled Numeric Formats"
- [ISCA'25] "Garibaldi: A Pairwise Instruction-Data Management Scheme for Enhancing Shared Last-Level Cache Performance in Server Workloads"
2. AI Accelerators and Neural Processing Units (NPUs)
The Shift Toward Dedicated AI Accelerators (NPUs)
Artificial Neural Networks (NNs) are powerful computing systems inspired by the biological structures of the human brain. They operate through interconnected nodes—or neurons—that process and transmit signals via weighted connections, which adjust dynamically during the learning phase. These neurons are aggregated into distinct layers, such as convolutional or fully-connected layers, enabling the network to model highly complex, nonlinear processes. Consequently, NNs have become the foundational technology driving modern breakthroughs in image recognition, speech processing, and natural language processing.
Historically, these highly compute- and memory-intensive algorithms have been executed on GPGPUs. However, because GPUs are inherently designed for general-purpose parallel computation, they often struggle to achieve optimal efficiency for specific neural network operations. To overcome these limitations and meet the massive computing demands of modern AI, both academia and industry are rapidly shifting toward Neural Processing Units (NPUs)—dedicated, specialized hardware accelerators explicitly engineered to provide maximum performance and energy efficiency for AI workloads.
What We Are Doing
Our lab focuses on the comprehensive modeling and design of advanced NPU cores. By deeply analyzing the unique operational characteristics of various neural network applications, we identify innovative ways to accelerate them efficiently. We achieve this by developing heavily optimized hardware architectures, customized memory systems, efficient data pipelines, and specialized Instruction Set Architectures (ISAs). Furthermore, we build detailed NPU simulators to rigorously evaluate power consumption, execution performance, and underlying system bottlenecks, ensuring our architectures are fully equipped to handle next-generation AI demands.
Recent Publications:
- [ISCA'26] "MXFFP: Microscaling Flexible Floating Point Format for Large-Scale AI Model Acceleration"
- [ISCA'26] "SLICE: A Selective Local Inference Framework with Codec Exploitation for Accelerating Video Super-Resolution"
- [NeurIPS'25] "Rethinking Entropy in Test-Time Adaptation: The Missing Piece from Energy Duality"
- [MICRO'25] "BitL: A Hybrid Bit-Serial and Parallel Deep Learning Accelerator for Critical Path Reduction"
- [ICCV'25] "Adversarial Purification via Super-Resolution and Diffusion"
- [ICCV'25] "WINS: Winograd Structured Pruning for Fast Winograd Convolution"
- [HPCA'25] "Ditto: Accelerating Diffusion Model via Temporal Value Similarity"
- [DAC'25] "CVMAX: Accelerator Architecture with Polar Form Multiplication for Complex-Valued Neural Networks"
3. Memory Systems and Processing-in-Memory (PIM)
Overcoming the Memory Wall Challenge
Modern data center applications—such as neural networks, graph processing, and large-scale databases—are fundamentally memory-intensive, demanding massive storage capacities and high data bandwidth. However, the traditional compute-centric computing paradigm struggles to execute these workloads efficiently. Because conventional architectures prioritize computational logic over data retrieval, they are bottlenecked by small on-chip memory capacities and physically long data-access distances. This creates a severe performance and energy bottleneck, often referred to as the "memory wall," where the act of moving data across the system costs significantly more time and power than the actual computation.
What We Are Doing
Domain-Specific Memory Systems
Breaking away from rigid, general-purpose memory hierarchies, we develop low-power, high-performance memory architectures explicitly tailored to unique applications, such as neural-network-specific storage and heterogeneous memory systems utilizing emerging memory technologies.Memory-Centric Computing Platforms
By shifting the architectural focus away from the processor, we develop Near-Data Processing (NDP) and Processing-in-Memory (PIM) solutions. By strategically embedding processing units directly within or adjacent to the memory and storage layers, we drastically minimize expensive data movement, accelerating operations for databases and enabling advanced, highly scalable architectures like rack-scale pooled memory.Recent Publications:
- [MICRO'26] "AMMA: A Multi-Chiplet Memory-Centric Architecture for Low-Latency 1M Context Attention Serving"
- [ISCA'26] "Reducing Page Faults via Invalidation-based Mapping Propagation in Multi-GPU Systems"
- [HPCA'25] "Marching Page Walks: Batching and Concurrent Page Table Walks for Enhancing GPU Throughput"
1. Quantum Algorithms and Programming
Architectural Frameworks for Quantum Execution
Quantum algorithms, such as variational quantum algorithms (VQAs) and the quantum approximate optimization algorithm (QAOA), provide the mathematical foundation for achieving quantum advantage. However, these algorithms cannot run directly on physical hardware without a sophisticated intermediary layer. In the current noisy intermediate-scale quantum (NISQ) era, hardware is characterized by limited qubit connectivity and high error rates. Architectural programming technologies are therefore essential to bridge the gap between high-level algorithmic intent and the specific physical constraints of different quantum processing units (QPUs).
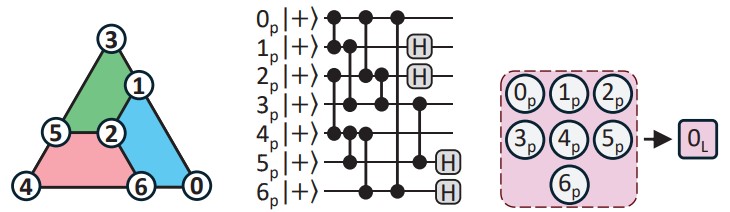
What We Are Doing
Our research objective is to develop automated, hardware-aware frameworks that optimize how quantum circuits are generated and managed. We focus on rewriting algorithms to fit specific hardware platforms and physical topologies, such as superconducting transmons, Rydberg arrays, and trapped ions, to ensure maximum fidelity and minimum runtime overhead during execution. Furthermore, we design architectural abstractions that improve resource efficiency through intelligent qubit reuse, dynamic shot optimization, and layer-wise parameter-freezing, significantly reducing the execution overhead required for practical quantum computing.

Recent Publications:
- [HPCA'26] "Toward Scalable Gate-Level Parallelism on Trapped-Ion Processors with Racetrack Electrodes"
- [ISCA'25] "QR-Map: A Map-Based Approach to Quantum Circuit Abstraction for Qubit Reuse Optimization"
- [CGO'25] "Qubit Movement-Optimized Program Generation on Zoned Neutral Atom Processors"
- [Quantum Mach. Intell. 8] "Layerwise Retraining and Freezing for Multi-Angle QAOA"
- [Phys. Rev. Research 7] "Distribution-Adaptive Dynamic Shot Optimization for Variational Quantum Algorithms"
2. Quantum Compilation and Pulse Control
The Hardware-Software Interface
Compilation and pulse control serve as the critical translation layers of the quantum computing stack. A quantum compiler maps logical qubits to physical ones and schedules gates to minimize error and execution time. At the lowest level, pulse-level control (or quantum optimal control) translates these logical gates into the exact analog waveforms—such as microwave or laser pulses—that physically manipulate qubit states. Precise coordination between these layers is necessary to mitigate hardware-level noise and decoherence.
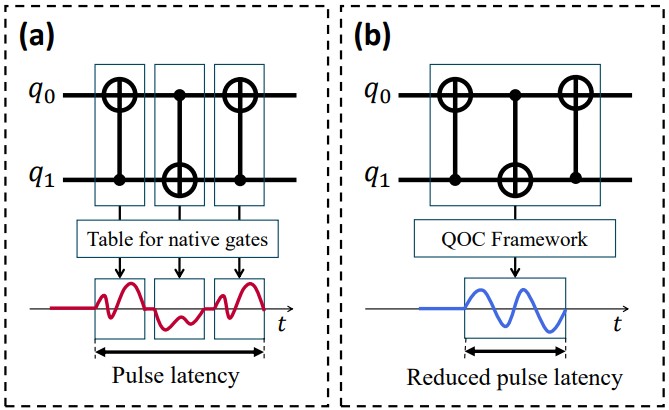
What We Are Doing
We investigate cross-stack co-design techniques that unify gate-level compilation with pulse-level optimization. Our research aims to improve instruction-level code through phase polynomial-based optimizations and native-aware ansatz generation tailored to specific hardware capabilities. We also develop causality-aware optimal control frameworks and error-mitigation strategies that actively compensate for thermal relaxation, ensuring that quantum operations are both accurate and scalable.
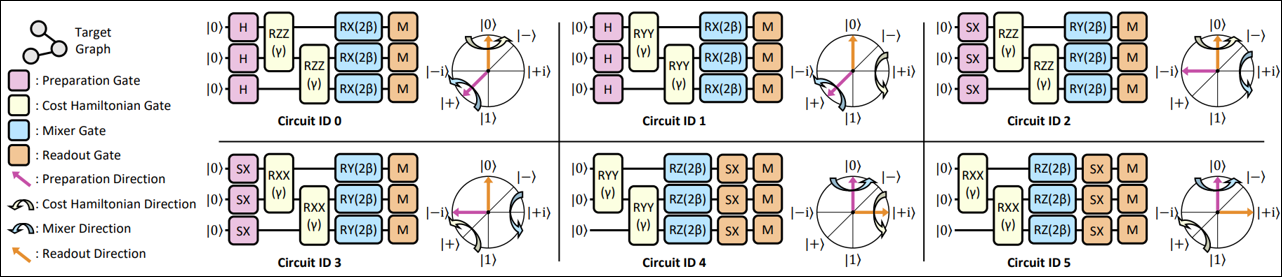
Recent Publications:
- [MICRO'26] "DARTH: Lookahead-Driven Compilation Exploiting Transient Qubits for Distributed Quantum Computing"
- [ISCA'26] "Leveraging Phase Polynomials for Quantum Circuit Optimization"
- [HPCA'26] "d'ArQ: A QOC Framework with Causality-Aware Grouping and Basis Selection"
- [ICCAD'24] "Barber: Balancing Thermal Relaxation Deviations of NISQ Programs by Exploiting Bit-Inverted Circuits"
- [PACT'24] "Recompiling QAOA Circuits on Various Rotational Directions"
- [DAC'23] "Quixote: Improving Fidelity of Quantum Program by Independent Execution of Controlled Gates"
3. Simulators
The Necessity of Classical Simulation
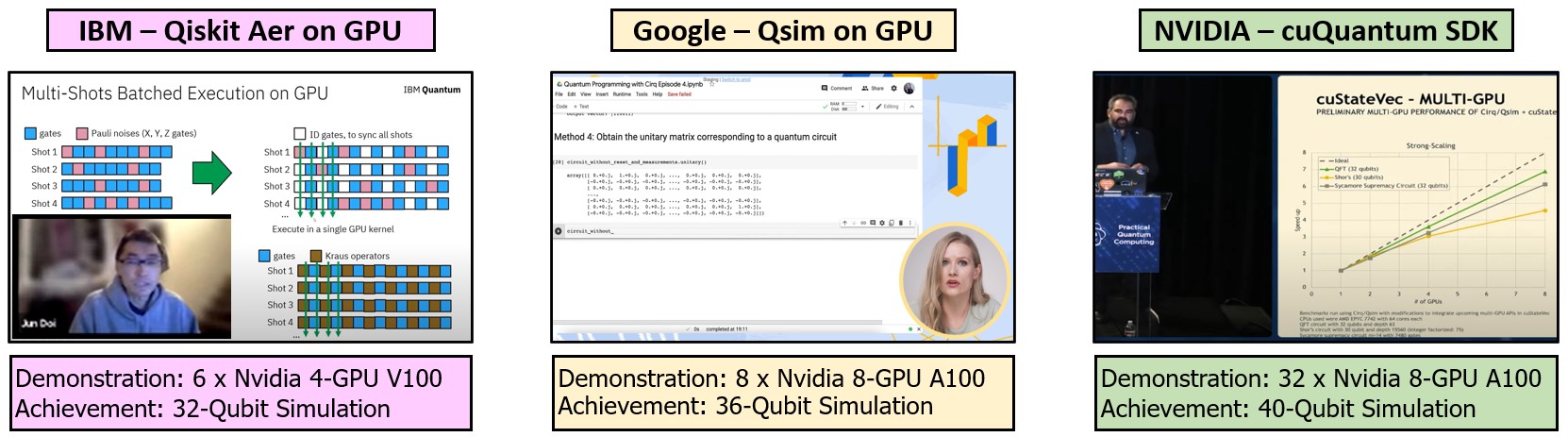
Because physical quantum computers are highly prone to noise, expensive, and difficult to access, simulating quantum circuits on classical supercomputers and GPUs is an absolute necessity for architectural research. However, simulating quantum states requires memory that grows exponentially with every added qubit. Simulating even moderately sized quantum systems quickly exhausts the memory bandwidth and compute limits of modern classical hardware.
What We Are Doing
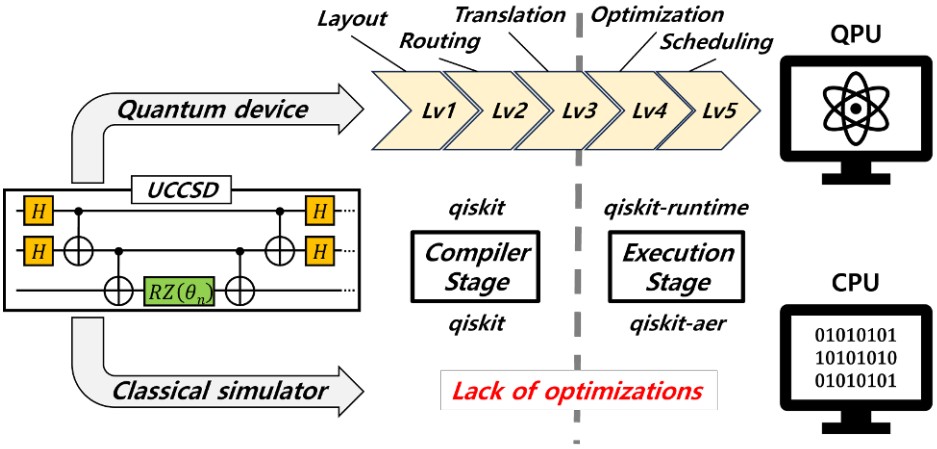
Our broad objective is to overcome the exponential "memory wall" of quantum simulation by designing high-performance, specialized simulation platforms. We explore architectural innovations such as processing-in-memory (PIM) to minimize data movement and maximize bandwidth for large-scale state-vector tracking. Additionally, we research efficient numeric representations, including polar form-based simulators, and hardware acceleration for complex chemistry workloads like UCCSD to make high-fidelity quantum verification accessible and efficient.
Recent Publications:
- [ASP-DAC'25] "PIMutation: Exploring the Potential of Real PIM Architecture for Quantum Circuit Simulation"
- [ICCD'24] "MOSQ: Accelerating Classical Simulation of UCCSD Ansatz Circuits using Merged Operation"
- [TETC 13] "q-Point: A Numeric Format for Quantum Circuit Simulation using Polar Form Complex Numbers"
Collaboration
Super Computing In Pocket (SCIP) Research Group in the Ming Hsieh Department of Electrical Engineering, University of Southern California
